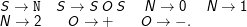Bei unserer Erkundung von Python wollen wir uns jetzt eine Weile von einem konkreten Projekt mit einiger Relevanz für die Computerlinguistik leiten lassen, nämlich der Interpretation von Phrasenstrukturgrammatiken.
Sprachen werden gerne durch Grammatiken generiert. Dabei schreiben Ersetzungsregeln vor, was in jedem Schritt wodurch abgeleitet werden kann, ausgehend von einem Startsymbol, das im Allgemeinen S heißt. Beispiel für Regeln:

Diese Regelmenge (mit der Menge der Nichtterminalen {S} und der Menge der Terminalen {a,b}) erzeugt eine Sprache, in der die gleiche Zahl von a-Symbolen ein b rechts und links umschließen – klassisch könnte das für balancierte Klammern stehen (d.h. genauso viele Klammern gehen zu wie vorher aufgegangen sind). Eine mögliche Ableitung wäre
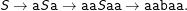
Für unsere Zwecke sollen Nichtterminalsymbole (die also noch ersetzt werden) vorerst durch Großbuchstaben dargestellt werden. Terminalsymbole (die nicht mehr ersetzt werden können und das schließlich erzeugte Wort ausmachen) sind dann alle anderen druckbaren Zeichen.
Weiter wollen wir uns auf kontextfreie Sprachen beschränken, also solche, bei denen auf der linken Seite der Regeln immer nur genau ein Nichtterminalsymbol steht. Wir lassen aber zu, dass auf der rechten Seite gar nichts steht (“ϵ-Regeln”).
Wir wollen ein Programm schreiben, das eine von so einer Regelmenge erzeugte Sprache berechnet. Überlegen wir uns zunächst die Datenstrukturen, wie wir brauchen. Wörter sind nach der obigen “Definition” Sequenzen von Terminalen und Nichtterminalen, also Großbuchstaben und anderen Zeichen. Mithin sind sie durch Strings ausreichend modelliert. Bei der Regelmenge müssen wir uns etwas mehr Gedanken machen. Sie ist letztlich eine Abbildung von Großbuchstaben auf Wörter (also Strings).
Der naive Ansatz zur Modellierung der Regelmenge, ein Dictionary von Strings:
rules = {
'S': 'b',
'S': 'aSa',
}
(Das Komma hinter der letzten Zeile im Initialisierer von rules ist syntaktisch legal und macht spätere Ergänzungen leichter) scheitert:
>>> rules
{'S': 'aSa'}
Oops – ein Schlüssel kann nur auf einen Wert verweisen. Abhilfe: Werte sind nicht mehr nur Strings, sondern Listen von Strings. Also:
rules = {
'S': ['b', 'aSa'],
}
Wir haben jetzt als die Datenstrukturen soweit festgelegt. Die Frage ist, was tun wir damit? Wir müssen jetzt also einen Algorithmus ersinnen, der auf den Daten korrekt operiert. Ganz grob gesprochen müssen wir einfach so lange Nichtterminale ersetzen, bis es entweder keine anwendbaren Regeln mehr gibt oder keine Nichtterminale mehr im betrachteten Wort stehen. Dieses Wort möchten wir dann ausgeben und nach neuen rein terminalen Wörtern suchen.
Zur genaueren Formulierung von Algorithmen, vor allem aber zur Strukturierung der eigenen Gedanken und zur späteren Dokumentation eines Programm wurden diverse Techniken entwickelt. Zumal bei komplizierteren Problemen lohnt es sich, vor der Implementation zunächst mit einer dieser Methoden festzulegen, was ein Programm eigentlich tun soll. In den Urzeiten wurden dazu Flussdiagramme eingesetzt, die ähnlich unserem Bild vom Control Flow aussahen (allerdings mit Schablonen und Kästchen etwas übersichtlicher waren). In solchen Flussdiagrammen lassen sich Kontrollstrukturen wie etwa Schleifen nur sehr krude darstellen, und generell sind die heute eher etwas für WirtschaftswissenschaftlerInnen als für ProgrammiererInnen, weil die Programmiersprachen selbst inzwischen viel problemorientierter sind als die Flussdiagramme.
Als in den siebziger Jahren die strukturierte Programmierung Mainstream wurde, schwörten viele Menschen eine Zeitlang auf so genannte Struktogramme oder Nassi-Shneidermann-Diagramme. Sie sind besser auf moderne Programmiersprachen abgestimmt und können zum Beispiel vernünftige Schleifen darstellen. Letztlich allerdings malt man dabei doch die meiste Zeit, und das Entwurfsniveau ist eher niedriger als etwa beim Entwerfen in Python selbst.
In den letzten 20 Jahren hat sich daher letztlich ein nicht allzu standardisierter Pseudocode als Mittel der Wahl durchgesetzt, um Algorithmen auf einem etwas höheren Niveau als dem der Zielsprache darzustellen. Zum Entwurf eines Programmsystems ist er aber in der Regel nicht ausreichend. Heutige Programme bestehen aus vielen Komponenten, die auf viele Arten wechselwirken – um dies zu modellieren, braucht man andere Werkzeuge; ein Stichwort dabei mag UML sein.
Zurück zu unserem Problem. Ein möglicher Algorithmus zur Durchführung einer Ableitung könnte sein:
Eingabe: Ein Wort mit mindestens einem Nichtterminalsymbol w, eine Regelmenge R
Sei e die leere Liste
Sei n das am weitesten links stehende Nichtterminalsymbol in w
für alle Regeln n→x in R
Füge den String, der durch Ersetzen des ersten Vorkommens von n in w durch x entsteht, zu e hinzu
Rückgabe: e, die Liste mit allen Ableitungen, die durch Ersetzen des am weitesten links stehenden Nichtterminals in w entstehen können – insbesondere die leere Liste, wenn keine passenden Regeln vorhanden sind.
Implementation des Ableiters:
def deriveLeft(curWord, rules): leftmostNonTerm = getLeftmostNonTerm(curWord) res = [] for right in rules.get(leftmostNonTerm, []): res.append(curWord.replace( leftmostNonTerm, right, 1)) return res
Diese Implementation spiegelt den Algorithmus von oben ziemlich genau wieder. Trotzdem sehen wir uns mal Zeile für Zeile an, was da so passiert:
- Zunächst sagen wir, dass die Funktion deriveLeft heißen soll, ein Wort (curWord) und die Regeln nehmen soll. In einem Docstring sollte eigentlich erklärt werden, dass curWord ein String sein soll und rules eine Abbildung von Nichtterminalen auf eine Sequenz von Ersatzstrings.
- Dann besorgen wir uns das am weitesten links stehende Nichtterminal. Diese Funktionalität hat eine so einfache Schnittstelle, dass wir sie in eine separate Funktion verlagert haben.
- Jetzt bereiten wir unsere Ergebnisliste vor. Wir haben noch keine Ergebnisse, also ist die Liste leer.
- Wir iterieren über alle möglichen rechten Seiten. Wenn unser Nichtterminal gar nicht als linke Seite auftritt, iterieren wir über die leere Liste, also gar nicht. Dann geben wir auch nur die leere Liste zurück.
- Für jede rechte Seite ersetzen wir das erste Vorkommen der linken Seite (fürs “erste” sorgt das letzte Argument des replace – die eins sagt, dass nur ein Zeichen ersetzt werden soll) durch die augenblickliche rechte Seite, die wir in right gespeichert haben.
- Dies ist eine Fortsetzungszeile. Seht euch bei Bedarf nochmal die Anmerkungen über die Syntax von Anweisungen oben an.
- Wir sind fertig und geben unser Ergebnis zurück.
Die Funktion getLeftmostNonTerm muss den ersten Großbuchstaben im String zurückgeben. Eine mögliche Implementation:
def getLeftmostNonTerm(word): for c in word: if c.isupper(): return c
Anmerkungen dazu:
- isupper ist eine Methode von Strings und gibt “wahr” zurück, wenn der betreffende String nur aus Großbuchstaben besteht.
- Wenn in word kein Großbuchstabe vorkommt, wird kein return-statement ausgeführt.
Python-Funktionen ohne return geben den Wert None zurück:
>>> print getLeftmostNonTerm("allesklein") None >>> if getLeftmostNonTerm("allesklein")==None: ... print "Kein Großbuchstabe" ... Kein Großbuchstabe
Wir speichern rules und die beiden Funktionen in gener1.py. Jetzt:
>>> from gener1 import *
>>> deriveLeft("S", rules)
['b', 'aSa']
>>> deriveLeft("baSb", rules)
['babb', 'baaSab']
Hier dürfen wir from gener1 import * mal machen: Im interaktiven Interpreter sparen wir uns damit Tipparbeit (und ich mir Platz auf den Folien). Das ist aber auch so in etwa der einzige legitime Einsatz.