Der Zugriff auf Dateien ist so komisch gemacht, weil Massenspeicher anders funktionieren als RAM (allerdings erlauben modernere Betriebssysteme, Dateien zu “mappen” und sie dann wie Arrays zu verwenden – wir werden das in unserer Python-Erweiterung verwenden).
Heute übliche Massenspeicher bestehen aus einer oder mehreren Platten, über denen je zwei Schreib-/Leseköpfe schweben. Mit ihnen kann man je eine Spur anfahren. Jede Spur ist nochmal in Sektoren zu je 512 Byte (oder Vielfachen davon) eingeteilt. Gängige Schnittstellen zu Platten (SCSI) liefern nie Bytes, sondern immer Sektoren.
Nach außen hin sehen nicht allzu antike Festplatten allerdings aus wie eine lange Sequenz von Sektoren – wie sie diese Sektoren intern auf Platten, Spuren und Sektoren verteilen, ist opak, d.h. nicht nach außen sichtbar. Das geht so weit, dass sie “kaputte” Sektoren einfach aus einer Art Reservepool ersetzen, ohne dass der Rechner überhaupt etwas davon merkt.
Für CDs ist diese Darstellung ohnehin die korrekte, denn sie haben als Erbe ihrer Audio-Herkunft wie die guten alten Schallplatten nur eine Spur, die sich spiralförmig über die ganze nutzbare Fläche windet – der Unterschied zu konzentrisch angeordneten Spuren kann für unsere Zwecke aber vernachlässigt werden.
Die immer üblicher werdenden Flash-Speicher sind eigentlich mehr mit RAM vergleichbar, da bei ihnen die direkte Adressierung einzelner Bytes wenigstens beim Lesen kein Problem wäre. Dennoch sehen die meisten Flash-Speicher nach außen auch wie eine Platte aus, lassen also nur Zugriff auf “Sektoren” zu. Dies wird vor allem gemacht, weil so gut wie jedes System weiß, wie man mit Platten umzugehen hat – aber auch, weil Flash-Speicher nur sektorenweise beschreibbar ist.
In der Regel ist der Zugriff auf Daten vom Massenspeicher erheblich langsamer als auf Daten im Hauptspeicher. Auch die Bandbreite der Leitung zwischen Platte und Prozessor oder RAM ist deutlich geringer als die zwischen Prozessor und RAM. Unter anderem deshalb unterhalten moderne Betriebssysteme disk caches, in denen vermutlich häufiger gebrauchte Daten von der Platte im RAM gespeichert werden.
Dateisysteme
Um die Daten auf der Platte sinnvoll zu organisieren, verwenden Betriebssysteme ein Dateisystem. Bei dieser Diskussion orientieren wir uns am Standard-Unix-Dateisystem, das weitgehende repräsentativ ist für die Art, in der die meisten Betriebssysteme ihren Massenspeicher verwalten. Als Dateisystem wird dabei sowohl eine konkrete Folge zusammenhängender Blöcke (das sind Gruppen von Sektoren konstanter Größe, wobei jeder Block je beispielsweise 4, 8, oder 16 Sektoren umfasst) bezeichnet, die für das Betriebssystem eine Verwaltungseinheit bilden, als auch die Datenstruktur, die zur Organisation der Blöcke dient. Im zweiten Sinn spricht man von einem ext2-Dateisystem, einem NTFS-Dateisystem, einem UFS-Dateisystem, einem ISO-9660-Dateisystem usf – sie unterscheiden sich alle nach der Art, wie sie die Daten im Detail organisieren.
Ein Dateisystem kann so aussehen:
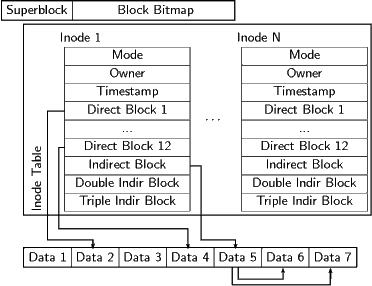
Ein Dateisystem beginnt mit dem Superblock, in dem beispielsweise drinsteht, wo das Wurzelverzeichnis zu finden ist, wie oft das Dateisystem gemountet wurde, wie groß es ist usf. Wegen seiner Wichtigkeit wird der Superblock häufig mehrfach gespeichert.
Es folgt eine Block Bitmap, in der für jeden Block ein Bit steht, das markiert, ob der betreffende Block frei ist oder nicht. Danach folgt eine Liste von so genannten Inodes. Jeder Inode entspricht einer Datei und gibt für diese Datei einerseits Metainformationen (Mode sagt etwas über die Zugriffsrechte, Owner ist der/die EigentümerIn der Datei, Timestamp sagt, wann die Datei zuletzt geändert wurde). Andererseits ist hier verzeichnet, in welchen Blöcken die Daten, die zu dieser Datei gehören, gespeichert sind. Dazu hat man zunächst 12 Blöcke, deren Nummern direkt im Inode stehen. Wenn Dateien wachsen, braucht man mehr Blöcke, für deren Nummern im Inode (dessen Größe ja festliegt) kein Platz mehr ist.
Um Dateien mit mehr als 12 Blöcken verwalten zu können, hat man den Indirect Block, der auf einen Block verweist, in dem weitere Blocknummern stehen, die dann ebenfalls zur Datei gehören. Wenn auch das nicht reicht, kann man in den Double Indirect Block benutzen – einen Block, in dem die Nummern von weiteren Indirect Blocks stehen. Was der Triple Indirect Block ist, könnt ihr euch selbst überlegen. Mithin sorgt das Dateisystem dafür, dass auf kleine Dateien besonders schnell zugegriffen werden kann, weil die zu ihnen gehörenden Blöcke direkt im Inode stehen. Dies ist für Unix-Systeme, auf denen man gerne viele kleine Dateien hat, recht günstig.
Der Rest der Platte wird von den durchnummerierten Datenblöcken eingenommen.
Moderne Dateisysteme sind noch um einiges komplizierter, weil man z.B. eine Fragmentierung von Dateien vermeiden will, die dann eintritt, wenn die zu einer Datei gehörenden Blöcke nicht mehr hintereinander liegen und der Lesekopf also wild über die ganze Platte hüpfen muss, um die Daten zu finden.
Ganz moderne Dateisystem (z.B. reiserfs) verlassen das hier dargestellte Konzept fast vollständig und haben evtl. nicht mal mehr wirkliche Inodes. Auf der anderen Seite haben auch ganz primitive Dateisysteme nichts, das wirklich Inodes entsprechen würde (vgl. unten).
Dateien haben keine Namen. Die Namen stehen in speziellen Dateien, den Directories. Von ihnen gehen Zeiger in die Inode Table, die den Namen mit einer Datei verbinden.
Dieses Vorgehen hat unter anderem den Vorteil, dass eine Datei unter mehreren Namen im Filesystem stehen kann (hard link).
In einfacheren Dateisystemen werden einige Dinge anderes gehandhabt, wenn auch die meisten Prinzipien ziemlich analog laufen. In FAT-Dateisystemen etwa, die bei DOS üblich waren und nach wie vor für Digitalkameras und ähnliches Standard sind, gibt es keine Inodes. Stattdessen enthält der Directoryeintrag die Metainformationen (bei FAT ist das im Wesentlichen das Datum der letzten Änderung), während die zur Datei gehörigen Blöcke über eine FAT (File Allocation Table) gefunden werden. Dabei hat jeder Block einen Eintrag in der FAT, der auf den ihm folgenden Block verweist. Der Verzeichniseintrag enthält nur den Index des ersten Blocks, an dem man dann nachsehen kann, wo der zweite Block liegt, woraus man wiederum die Lage des dritten Blocks ersehen kann und so fort.