Die tschebytschewsche Ungleichung für eine Zufallsvariable X lautet
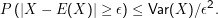
Beweis: Sei Z= X-E(X), also einfach X, nur auf Erwartungswert Null getrimmt. Definiere neue Zufallsvariable Y mit
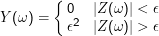
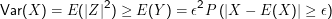
Große Abweichungen vom Erwartungswert werden um so unwahrscheinlicher, je kleiner die Varianz ist.
Wichtige Folge: Das ” schwache Gesetz der großen Zahlen“.
Seien X1,…,Xn i.i.d. Zufallsvariable mit beschränkter Varianz. Sei Hn = 1∕n∑ i=1nXi. Es gilt mit ϵ >0 und einer Konstanten M:
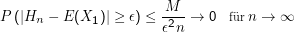
Beweis: Wegen der Linearität des Erwartungswerts und unserer i.i.d.-Annahme ist E(Hn) = E(X1). Außerdem ist
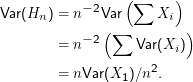
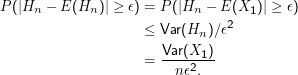
Das ist mit M= Var(X1) der eine Teil der Behauptung. Der andere folgt, weil M und ϵ konstant sind und 1∕n für große n gegen Null geht.
Die Aussage ist also, dass bei vielen identischen Experimenten die Wahrscheinlichkeit, dass die Summe der Ergebnisse geteilt durch die Zahl der Ergebnisse (der Mittelwert einer Meßreihe) weit vom Erwartungswert abliegt, beliebig klein wird.
Tatsächlich ist die Abschätzung aus dem Gesetz der großen Zahlen bzw. aus der tschebytschewschen Ungleichung in aller Regel zu pessimistisch, gibt also relativ große Grenzen für die Wahrscheinlichkeit an, die normalerweise bei weitem nicht erreicht werden. Der Grund dafür ist die große Allgemeinheit von Tschebytschew, der sozusagen noch für die übelsten Verteilungen (etwa mit zwei ganz spitzen Maxima) gelten muss, während die meisten Verteilungen, denen man im Alltag so begegnet, viel netter sind. Wie man ” bessere“ (man sagt auch gern ” schärfere“) Abschätzungen bekommt, werden wir noch sehen.
Diese Formel liefert den Zusammenhang zwischen experimentell ermittelbaren relativen Häufigkeiten und einem Parameter der Verteilung.
Beispiel: Ω seien die Wörter eines deutschen Textes, die Zufallsvariable ist die Länge eines ” zufällig“ gezogenen Worts. Es kann dann sein:
| X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 | X10 |
| 11 | 4 | 13 | 4 | 7 | 8 | 9 | 6 | 6 | 6 |
Sei von irgendwo bekannt, dass Var(X) = 12 (also die Wortlänge in irgendeinem Sinn typisch um 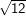 ≈3.5 vom Erwartungswert
abweicht).
≈3.5 vom Erwartungswert
abweicht).
Es ist H4 = 8, die Wahrscheinlichkeit, dass die tatsächliche mittlere Wortlänge des Deutschen um zwei oder mehr (also ϵ= 2) von 8 abweicht, also höchstens 12∕22∕4 = 0.75 (die Abschätzung ist nicht sehr gut… ). Die Wahrscheinlichkeit, dass sie um 5 oder mehr von 8 abweicht, ist höchstens 12∕52∕4 = 0.12
Es ist H10 = 7.4. Abweichung um 5 oder mehr mit höchstens 0.048, Abweichung um 1 oder mehr mit höchstens 1.2.