Mutual Information
Wegen der Kettenregel ist H(X) -H(X|Y) = H(Y) -H(Y|X). Diese Größe heißt relative Entropie, Transinformation oder meistens Mutual Information I(X;Y). Sie ist offenbar 0 für unabhängige X, Y und wächst mit dem Grad der Abhängigkeit wie auch der Entropie der einzelnen Zufallsvariablen. Schließlich ist I(X;X) = H(X).
Zur konkreten Berechnung der Mutual Information kann
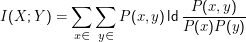
Eine Anwendung der Mutual Information ist das noisy channel model. Dabei überträgt man Information (modelliert durch eine Zufallsvariable X) über einen Kanal, der dem Signal ” Rauschen“ hinzufügt und bekommt am anderen Ende eine Zufallsvaribale Y heraus. Beispiele für solche Kanäle können Funkstrecken sein (etwa zu Mobiltelefonen), ein Zyklus von Drucken und Scannen, aber auch Übersetzung oder der Weg von gesprochener Sprache zur Ausgabe des Spracherkenners.
Ziel eines Übertragungssystems ist nun, dass Y so viel wie möglich mit X ” gemeinsam“ hat, also die Mutual Information zu maximieren. Es ist klar, dass keine Informationsübertragung mehr möglich ist, wenn X und Y unabhängig sind – das ist gerade der Fall I(X;Y) = 0. Ist die Übertragung perfekt, so ist X= Y, damit also I(X;Y) = H(X), was bedeutet, dass alle Information, die in X steckte, auch in Y steckt.
Kullback-Leibler Divergence
Ebenfalls gern als relative Entropie bezeichnet wird die Kullback-Leibler Divergence
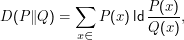
Bei der Bildung einer Modellverteilung Q für eine Zufallsvariable X mit ” wahrer“ Verteilung P möchten wir, dass die KLD von Q und P möglichst gering wird. Wir kennen aber P nicht.
Umweg: Die Kreuzentropie eines mit P verteilten X und einer Verteilung Q ist
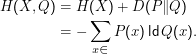
Für Nachrichten L(n) = x1,…,xn, die nach P gezogen wurden, ist die Kreuzentropie pro ” Zeichen“
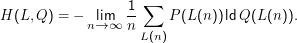
Für ein stationäres, ergodisches Sprachmodell ” mittelt“ sich das P aber heraus, und es gilt
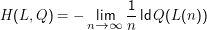
Die Perplexität einer Schätzung ist 2H(L,Q).
Es gibt eine andere Interpretation dieser Größe: Nehmen wir an, wir hätten ein Sprachmodell P(w|h), das zu jeder Vorgeschichte h die Verteilung des nächste Worts/Zeichens w ergibt. Für festes w und h nennen wir H(w|h) = -ldP(w|h) die punktweise Entropie.
Die punktweise Entropie bemisst, wie schlecht eine Beobachtung zu einem Modell passt, also sozusagen die ” Überraschung“ unter dem Modell. Ist z.B. in einem Bigramm-Modell sicher, dass nach einem q ein u kommt, so ist P(u|q) = 1; der Logarithmus ist 0, entsprechend sind wir nicht überrascht, wenn wir das Wort qualitätsmanagement sehen (was insgesamt eher beunruhigend ist). Wenn nun aber die Marketing-Abteilung der Sirius Cybernetics Corporation beschließt, dass Überraschung den Verkauf fördert und qwest für einen tollen Namen hält, wird unser System versuchen, den Logarithmus aus P(w|q) = 0 zu ziehen und seine ” unendliche“ Überraschung durch einen Laufzeitfehler kundtun.
Summiert man die punktweisen Entropien über eine ganze Nachricht, bekommt man ein Maß für die Wahrscheinlichkeit dieser Äußerung unter unserem Modell – wir werden so etwas ähnliches später beim Forward-Algorithmus von Markow-Ketten kennenlernen. Und eben dies ist unsere empirische Kreuzentropie.
Nochmal: Es wäre natürlich besser, die KLD angeben zu können, da wir ja eigentlich nur sagen wollen, wie falsch wir mit unserer Schätzung liegen. In realen Situationen kennen wir aber weder P(X) noch H(X) (also die Entropie des Phänomens, das wir modellieren wollen), und daher ist die Kreuzentropie oder die Perplexität die beste Größe, um die Qualität des Modells zu bemessen. Darin wird natürlich immer die Entropie des zugrundeliegenden Modells stecken, aber wir wissen immerhin, wann unser Modell besser geworden ist.
Dem oben verwendeten Begriff ” stationär“ werden wir bei Markow-Ketten nochmal begegnen: Die Wahrscheinlichkeiten P(w|h) ändern sich nicht mit der ” Zeit“ (also der Position im Datenstrom). Mit ergodisch bezeichnen wir demgegenüber Prozesse, bei denen ”Zeitmittel gleich Scharmittel“ ist. Das meint, dass in einer langen Nachricht (Zeit) die Elemente tatsächlich so verteilt sind, wie das die Verteilungsfunktion (Schar) erwarten lässt. Prozesse können nichtergodisch sein, wenn sie ” Senken“ (wenn also z.B. das Modell nur noch b erzeugt, wenn es einmal b erzeugt hat) oder Zyklen (nach einem b kann nur noch ababab… kommen) enthalten.
Exkurs: Algorithmische Information
Ein alternativer Informationsbegriff ist der der algorithmischen Entropie oder Kolmogorov-Komplexität. Dabei definiert man als Informationsgehalt einer Nachricht die Zahl der Bits, die man mindestens braucht, um eine universelle Turingmaschine so zu programmieren, dass sie die Nachricht reproduziert.
Auch dabei wird die Entropie nicht plötzlich eine der Nachricht innewohnende Eigenschaft – man muss sich zunächst darauf einigen, wie man die universellen Turingmaschine programmiert. Allerdings kann man hier zeigen, dass sich verschiedene Maße algorithmischer Komplexität nur um eine additive Konstante unterscheiden – die zwar groß sein kann, aber doch nur additiv. In diesem Sinn geht die algorithmische Informationstheorie viel mehr auf die Nachricht selbst ein als unsere Shannon-Theorie.
Eine Möglichkeit, Turingmaschinen zu beschreiben, haben wir in den formalen Grundlagen der Linguistik kennengelernt. Einigt man sich auf diese Beschreibung, die mit Nullen und Einsen auskommt, reduziert sich das Problem der Bestimmung der algorithmischen Information darauf, die kürzeste Beschreibung (also sozusagen das kürzeste Programm) zu finden, das die Nachricht produziert und dann zu zählen, wie viele Nullen und Einsen darin vorkommen. Leider ist es in der Regel unmöglich, tatsächlich zu zeigen, dass eine Beschreibung die kürzestmögliche ist.
Allgemein gilt, dass die algorithmische Information einer Nachricht nicht berechenbar ist (das lässt sich ganz analog zur Nichtentscheibarkeit des Halteproblems beweisen). Trotzdem lassen sich mithilfe der algorithmischen Information viele wichtige Theoreme beweisen – die aber leider nicht hierher gehören.
Der Zusammenhang zwischen Shannon’scher Entropie und Kolmogorov-Komplexität ist subtil, auch wenn er natürlich existiert. So kommen beispielsweise beide Begriffe zum Ergebnis, dass ich im Mittel ldn bits brauche, um gleichverteilte Zahlen zwischen 1 und n zu übertragen – auch Turing-Maschinen können nicht hexen.