Ziel der Klassifikation ist, bestimmte Versuchsausgänge einer von potenziell vielen Klassen zuzuordnen. Beispiele wären: Artikel in Klassen wie ” Klatsch“, ” Politik“, ” Feuilleton“ einteilen, Mails in Spam oder Ham, Spektren in verschiedene Stern- oder Galaxiensorten, Betriebszustände in normal, kritisch und ” Good Bye, Heidelberg“ und so weiter.
Formal wir haben Klassen vj ∈V und ” Trainingsdaten“ D⊂Ω ×V (also Paare von Beobachtungen und gewünschten Klassen, z.B. (Artikel1, Klatsch), (Artikel2, Politik) usf.). Wir haben weiter Hypothesen hi ∈H, deren jede eine Verteilung P(vj,ω|hi) gibt (also letztlich sagt, zu welcher Klasse vj ein ω gehören soll). Die bayes-optimale Klassfikation eines Ergebnisses ω ist dann
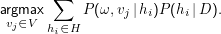
Im Groben addieren wir also für jedes vj einfach die von allen Hypothesen hi ausgespuckten Wahrscheinlichkeiten, dass ω von der Klassevj ist mal die Wahrscheinlichkeit der Hypothese selbst unter den gegenbenen Trainingsdaten – diese Rechnung ist richtig, weil die Ereignisse ” vj ist die korrekte Klassifikation“ disjunkt sind.
Bei nur zwei Hypothesen ist das Ergebnis des Klassifizierers natürlich das Gleiche, als hätte man zunächst die MAP-Hypothese bestimmt und dann nach dieser klassifiziert. Schon bei drei Hypothesen kann das aber anders sein. Sei etwa P(h1,2,3 |D) = 0.4,0.3,0.3. Wir könnten nun für ein ω etwas wie P(1,ω|h1) = 1 und P(0,ω|h2) = P(0,ω|h3) = 1 haben, d.h. die Hypothese h1 klassifiziert sicher als 1, die beiden anderen sicher nach 0. Die MAP-Hypothese ist damit h1, die danach wahrscheinlichste Klassifikation also 1. Unser Bayes-optimaler Klassifzierer würde hingegen
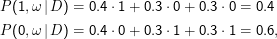
Man kann zeigen, dass es für einen gegebenen Hypothesenraum und gegebene Trainingsdaten keinen im Mittel besseren Klassifizierer gibt, dass also kein anderes Verfahren ” meistens“ bessere Ergebnisse liefert.
Leider ist der Bayes-Optimale Klassifizierer – wie eigentlich die meisten ” optimalen“ Verfahren in der Regel völlig unpraktikabel, weil – jedenfalls ohne weitere Annahmen – H gigantisch sein sollte (versucht, einen Hypothesenraum zur wortbasierten Klassifikation von Dokumenten in Dokumentenklassen zu bestimmen) und damit die Summe nicht realistisch berechenbar ist, von den Problemen, die P(hi |D) schätzen, ganz zu schweigen.
Naive Bayesian
Unser typisches Klassifikationsproblem ist die Zuordnung einer Sammlung von Werten x= ⟨a1,…,an⟩ zu einer Klasse v∈V. Diese Werte können etwa alle word tokens in einem Dokument sein oder die word tokens, die in der Umgebung eines bestimmten word types vorkommen.
Zur Klassifikation müssen wir lediglich
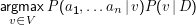
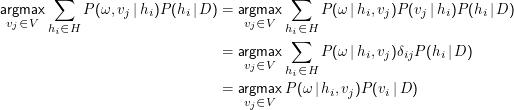
Diese Vereinfachung hilft noch nicht viel: Schon, wenn die ai aus kleinen Mengen kommen, gibt es furchtbar viele a1 , … , an. Nehmen wir etwa an, wir hätten 10 Klassen und wollten auf der Basis von 1000 Wörtern klassifizieren. Außerdem sehen wir nur auf Vorkommen von Wörtern (und nicht auf ihre Frequenzen), so dass wir eben 1000 ai haben, die die Werte 0 oder 1 annehmen können. Wie viele Werte von P(a1,…,an|v) müssen wir schätzen? Das Urnenmodell (hier haben wir ” Ziehung von 1000 Kugeln aus 2 mit Zurücklegen und mit Anordnung, also den Fall I) sagt uns, dass wir pro Klasse 10002 und mithin insgesamt 107 Parameter schätzen müssten. Das sind furchtbar viele. Deshalb:
Naive Bayesian Assumption:
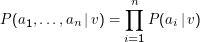
Das heißt nichts anderes, als dass das Auftreten des Attributs ai von dem des Attributs aj unabhängig ist. Das ist für unsere typischen Aufgaben grober Unfug, wie schon unser Beispiel mit Bundeskanzler und Schröder bei der Unabhängigkeit gezeigt hat. Trotzdem funktioniert der Naive Bayesian Classifier
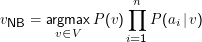
Hier reicht zum Training die Schätzung der n|V| Parameter P(ai|v).
Als Beispiel mag das Filtern von Spam dienen. V besteht dann aus den beiden Klassen Ham (Mails, die wir bekommen möchten) und Spam (also unerwünschte Werbemail). Die Attribute können zunächst alle Wörter sein, die wir in den Mails vorfinden.
Wir brauchen also zwei Sammlungen von Spam und Ham (das D, sozusagen unser Korpus) und schätzen (ML tut es hier) die Verteilungen P(w|Spam) und P(w|Ham) für alle word types w, die wir in D finden. Kommt nun eine neue Mail ω, berechnen wir P(ω,Spam|D) und P(ω,Ham|D) – die Zahlen werden typischerweise sehr klein werden, es empfiehlt sich also, hier mit logarithmischen Wahrscheinlichkeiten zu operieren – und entscheiden uns für die wahrscheinlichere Klasse.
Das funktioniert, ist aber nicht so sonderlich gut, weil die Naive Bayesian Assumption von Mails und unseren Fragen an sie erheblich verletzt wird. Wie es etwas besser geht, steht auf der nächsten Folie.