Praktisch alle Anwendungen von HMMs beruhen auf der Beantwortung von folgenden Fragen:
- Wie wahrscheinlich ist eine Beobachtung O in einem gegebenen Modell μ?
- Was ist die wahrscheinlichste Erklärung für die Beobachtung O unter einem Modell μ?
- Sei eine Beobachtung O und ein Menge M= {μ(ϑ)|ϑ∈Θ} möglicher Modelle gegeben. Welches Modell μ(ϑ0) erklärt O am besten?
Wir sprechen hier immer von Beobachtung, wo wir vorher von Ausgabe gesprochen haben; Hintergrund ist, dass HMMs fast nie zur Generierung von Sequenzen verwendet werden, sondern fast immer zur a-posteriori-Erklärung von beobachteten Sequenzen. Das ist auch der Hintergrund des Wortes ” hidden“: Man sieht nur das Ergebnis des HMM, die Folge der Zustände ist zunächst versteckt.
Die dritte Frage stellt sich im Allgemeinen als Lernproblem. Wir haben viele Beobachtungen und wollen zunächst ein HMM trainieren, die Parameter (ϑ wird meist vektorwertig sein) also so einstellen, dass sie den Beobachtungen maximal gut angepasst sind. Mit dem trainierten HMM können dann Fragen vom Typ 2 beantwortet werden.
Das erste Problem
Was ist die Wahrscheinlichkeit für eine Beobachtung O?
Eigentlich einfach: Wir rechnen für alle möglichen Zustandsfolgen X= (X1,…,XT+1) die individuellen Wahrscheinlichkeiten P(O|X,μ) aus und addieren sie.
Diese Wahrscheinlichkeiten sind tatsächlich einfach auszurechnen.
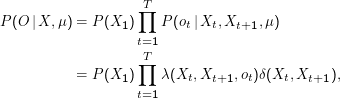
Es ist nicht schwer zu zeigen, dass die einzelnen P(O|X,μ) unabhängig sind, also eine schlichte Addition dieser Größen die gesuchte Gesamtwahrscheinlichkeit liefert.
Problem: Laufzeit ist ewig, man braucht (2T+ 1)NT+1 Multiplikationen für N Zustände.
Dynamic Programming
Abhilfe ist das dynamic programming. Idee dabei ist, einmal berechnete Werte in Tabellen zu halten. Der Begriff kommt aus einer sehr allgemeinen Form des Programmbegriffs, es lohnt nicht, allzu viele Gedanken auf ihn zu verschwenden.
Dazu: Tabelle (Trellis)
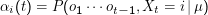
Dazu zählen wir die Zustände des HMM einfach irgendwie durch. Der Index i von αi(t) ” durchläuft“ dann alle möglichen Zustände,
der Parameter t die Zustandsfolge. Im fertigen Trellis stehen die Wahrscheinlichkeiten dafür, nach der Beobachtung von o1 ot-1
zum Zeitpunkt t im Zustand i zu landen.
ot-1
zum Zeitpunkt t im Zustand i zu landen.
Aufbauen der Tabelle: αi(1) = δik mit k Index des Startzustands; von dort ” nach vorne“ (d.h. zu späteren Zuständen hin) durcharbeiten:
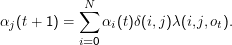
δij ist das Kronecker-Symbol
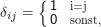
Danach werden einfach die Wahrscheinlichkeiten aller Übergänge, die auf den augenblicklichen Zustand führen können und dabei ot emittieren, aufsummiert.
Ein Bild mag helfen; hier die Berechnung von α2(t+ 1):
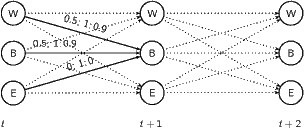
Sei α1 (t) = 0.15, α2(t) = 0.05, α3(t) = 0.02. Wenn von t auf t+ 1 eine 1 emittiert wurde, ist
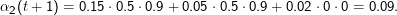
Die totale Wahrscheinlichkeit für die Beobachtung O ist dann
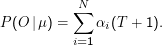
Wir berechnen hier also einfach die Summe der Wahrscheinlichkeiten, dass das Modell bei der gegebenen Ausgabe im Zustand i endet. Bei vielen Markow-Modellen werden ziemlich viele der αi(T+ 1) null sein, z.B. für alle Zustände, die gar keine ankommenden Übergänge haben, die das letzte Zeichen emittieren.